Data Flow in GCP
In the era of digital transformation, data has emerged as the lifeblood of modern enterprises. From informing strategic decisions to driving operational efficiency, businesses rely on the seamless flow of data across their ecosystems. Google Cloud Platform (GCP) stands at the forefront of empowering organizations to harness the power of data through its robust suite of services tailored for data processing, storage, and analysis.
Contents
Data Flow in GCP
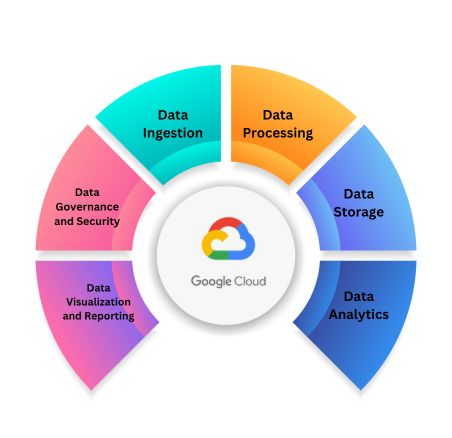
At the heart of GCP’s data ecosystem lies the concept of “Data flow in GCP,” which encompasses the seamless movement and transformation of data throughout its lifecycle. From ingestion to analysis, GCP offers a comprehensive set of tools and services designed to facilitate every aspect of the data flow journey.
Why Data Flow Matters?
In today's hyper-connected world, the ability to efficiently manage Gcp data flow has become a strategic imperative for businesses across industries. Whether it's capturing real-time insights from streaming data sources or analyzing vast volumes of historical data for predictive analytics, the ability to orchestrate data flow is critical for staying competitive in the digital age.
Key Components of Data Flow in GCP
Data flow in GCP revolves around several key components, each playing a vital role in enabling the seamless movement and transformation of data:
- Data Ingestion: The process of collecting data from various sources and bringing it into the GCP environment. This may include streaming data from IoT devices, logs, social media feeds, or batch data from on-premises databases.
- Data Processing: Once ingested, data needs to be processed and transformed to extract meaningful insights. Google Cloud Dataflow, a fully managed service based on Apache Beam, enables developers to build and execute data processing pipelines at scale, supporting both batch and real-time processing scenarios.
- Data Storage: GCP provides a range of storage solutions to accommodate diverse data types and use cases. Google Cloud Storage offers scalable and durable object storage, while Google Cloud Bigtable provides high-performance NoSQL storage for real-time analytics. Additionally, Google Cloud BigQuery serves as a fully managed data warehouse for storing and querying massive datasets with lightning-fast SQL queries.
- Data Analysis and Visualization: Once data is processed and stored, it can be analyzed and visualized to derive actionable insights. Google Cloud BigQuery’s serverless architecture enables ad-hoc querying and real-time analytics, while tools like Google Data Studio allow users to create interactive dashboards and reports for data visualization.
Foundational Concepts
Before going deeper into the intricacies of data flow in GCP, it’s essential to establish a solid understanding of the foundational concepts that underpin this process. These concepts serve as the building blocks upon which GCP’s data flow capabilities are built, encompassing everything from data ingestion to processing, storage, and analysis.
Data Ingestion
Data ingestion refers to the process of collecting and importing data from various sources into the GCP environment for further processing and analysis. In GCP, data can be ingested through both streaming and batch methods, depending on the nature of the data and the requirements of the use case.
- Streaming Data Ingestion: Streaming data ingestion involves the continuous collection and processing of data in real-time as it is generated. Google Cloud Pub/Sub, a fully managed messaging service, serves as a cornerstone for streaming data ingestion in GCP, enabling the seamless integration of data from diverse sources such as IoT devices, sensors, and application logs.
- Batch Data Ingestion: In contrast, batch data ingestion involves the periodic import of data in predefined batches. Google Cloud Storage, GCP’s scalable object storage solution, is commonly used for batch data ingestion, allowing organizations to upload large volumes of data from on-premises systems or other cloud environments.
Data Processing and Transformation:
Once data is ingested into GCP, it undergoes processing and transformation to extract valuable insights and prepare it for further analysis. Google Cloud Dataflow emerges as a powerful tool for orchestrating data processing pipelines in GCP, offering a fully managed and scalable solution based on the Apache Beam programming model.
- Apache Beam: Apache Beam is an open-source, unified programming model for building data processing pipelines that can run on various execution engines, including Dataflow, Apache Spark, and Apache Flink. By providing a unified API for both batch and streaming processing, Apache Beam simplifies the development and deployment of data processing workflows in GCP.
- Dataflow: Google Cloud Dataflow extends the capabilities of Apache Beam by offering a fully managed service for executing data processing pipelines at scale. With Dataflow, developers can focus on writing business logic without worrying about infrastructure management, as the service automatically handles tasks such as resource provisioning, scaling, and monitoring.
In the era of digital transformation, data has emerged as the lifeblood of modern enterprises. From informing strategic decisions to driving operational efficiency, businesses rely on the seamless flow of data across their ecosystems. Google Cloud Platform (GCP) stands at the forefront of empowering organizations to harness the power of data through its robust suite of services tailored for data processing, storage, and analysis.
Data Storage Solutions
Effective data storage is essential for ensuring the durability, accessibility, and scalability of data within the GCP environment. Google cloud data flow offers a range of storage solutions tailored to accommodate diverse data types and use cases including:
- Google Cloud Storage (GCS): Google Cloud Storage provides scalable and durable object storage for storing unstructured data such as images, videos, and log files. With features such as multi-regional replication and lifecycle management, GCS offers high availability and cost-effective storage options for a wide range of use cases.
- Google Cloud Bigtable: Google Cloud Bigtable is a fully managed NoSQL database service designed for real-time analytics and high-throughput, low-latency applications. With support for massive datasets and automatic scaling, Bigtable enables organizations to ingest and analyze large volumes of data with sub-millisecond latency.
- Google Cloud BigQuery: Google Cloud BigQuery serves as a fully managed data warehouse solution for storing and querying massive datasets with lightning-fast SQL queries. With its serverless architecture and built-in machine learning capabilities, BigQuery enables organizations to derive actionable insights from their data in real-time.
Google Cloud Dataflow Concepts
Google Cloud Dataflow is a fully managed service for stream and batch data processing. Understanding its core concepts is essential for building efficient data pipelines
1. Pipeline
- Definition: A pipeline is a series of steps that define the flow of data from input to output.
- Components: It includes sources, transformations, and sinks.
2. PCollection
- Definition: PCollection (parallel collection) is the main data structure in Dataflow, representing a distributed dataset.
- Types: PCollection can be bounded (fixed size, for batch processing) or unbounded (infinite, for stream processing).
3. Transforms
- Definition: Operations that process data within the pipeline.
- Common Transforms:
- ParDo: A parallel do operation, used for element-wise processing.
- GroupByKey: Groups elements by a key.
- Combine Aggregate data across a PCollection.
- Flatten: Merges multiple PCollections into one.
Partition: Splits a PCollection into multiple smaller collections.
4. Source and Sink
- Source: The input point for data in the pipeline, such as Pub/Sub, Cloud Storage, or BigQuery.
- Sink: The output point where processed data is written, such as Cloud Storage, BigQuery, or Pub/Sub.
5. Pipeline Runner
- Definition: Executes the pipeline.
- Types: Google Cloud Dataflow (managed service), Apache Flink, Apache Spark, etc.
6. Windowing
- Definition: Divides a PCollection into logical windows to perform computations on subsets of the data.
- Types:
- Fixed Windows: Divides data into equally sized windows.
- Sliding Windows: Windows that overlap by sliding over the data.
- Session Windows: Defined by periods of activity separated by gaps of inactivity.
7. Triggers
- Definition: Determines when results for a window are emitted.
- Types:
- Event Time Trigger: Based on timestamps in the data.
- Processing Time Trigger: Based on the system clock.
- Composite Trigger: Combination of multiple triggers.
8.Stateful Processing
- Definition: Maintains and updates state information across elements of a PCollection, useful for complex event processing.
- Use Cases: Tracking session state, managing counters, and aggregating data over time.
9. Side Inputs
- Definition: Provides additional data to a ParDo transform, allowing access to auxiliary datasets.
- Use Cases: Joining main data with smaller reference datasets.
10. Debugging and Monitoring
- Tools: Dataflow provides tools like Stackdriver for logging, monitoring, and debugging pipelines.
- Features: Real-time dashboards, logs, metrics, and alerting.
Gcp dataflow use cases
Google Cloud Dataflow is a versatile, fully managed service for stream and batch data processing.
1. Real-Time Analytics
- Scenario: Processing and analyzing streaming data in real time from sources like IoT devices, social media feeds, or log files.
- Example: Analyzing sensor data from smart devices to monitor and predict maintenance needs.
2.ETL (Extract, Transform, Load)
- Scenario: Extracting data from various sources, transforming it to a suitable format, and loading it into a data warehouse or database.
- Example: Moving and transforming data from on-premises databases to Google BigQuery for large-scale analytics.
3. Data Ingestion and Processing
- Scenario: Ingesting data from diverse sources such as APIs, cloud storage, and databases, and processing it for downstream applications.
- Example: Aggregating and cleaning data from multiple API endpoints and storing the processed data in Cloud Storage.
4. Machine Learning Pipelines
- Scenario: Preprocessing large datasets for machine learning models, including data cleaning, normalization, and feature extraction.
- Example: Preparing large-scale image data for training a machine learning model on the Google AI Platform.
5. Log Analysis
- Scenario: Collecting, processing, and analyzing log data from applications and infrastructure to monitor performance and detect anomalies.
- Example: Real-time analysis of server logs to detect and respond to security threats.
6. Data Integration
- Scenario: Integrating data from various sources to provide a unified view for business intelligence and reporting.
- Example: Combining sales data from different regions and platforms to generate comprehensive sales reports.
7.Event-Driven Processing
- Scenario: Processing and responding to events as they occur, such as user actions on a website or transactions in an e-commerce platform.
- Example: Updating user recommendations in real-time based on recent browsing and purchase behavior.
8. IoT Data Processing
- Scenario: Handling large volumes of data generated by IoT devices, performing real-time analytics, and storing the data for further analysis.
- Example: Monitoring and analyzing data from connected vehicles to optimize fleet management and reduce downtime.
9. Data Warehouse Modernization
- Scenario: Modernizing legacy data warehouses by migrating data and processing workloads to a cloud-native data warehouse like BigQuery.
- Example: Continuously ingesting and transforming legacy data for analysis in BigQuery, ensuring minimal downtime and data consistency.
10. Financial Transactions Processing
- Scenario: Processing financial transactions in real time to detect fraud, ensure compliance, and provide instant analytics.
- Example: Real-time monitoring and analysis of credit card transactions to detect and prevent fraudulent activities.
Google dataflow architecture
A managed service for processing batch and stream data is Google Dataflow. It is designed to simplify the development and execution of data processing pipelines.
1. SDK (Software Development Kit)
- Purpose: Allows developers to define pipelines using programming languages like Java and Python.
- Features: Provides a high-level API for constructing complex data processing workflows.
2. Execution Engine
- Responsibilities: Manages the deployment, execution, and monitoring of the pipeline.
- Features:
- Auto-Scaling: Dynamically adjusts resources based on workload.
- Fault Tolerance: Automatically retries failed operations and handles errors gracefully.
3. Job Management
- Job Submission: Pipelines are submitted as jobs.
- Job Monitoring: Provides tools to monitor job progress, view logs, and troubleshoot issues.
4.Optimization
- Auto-Tuning: Optimizes the execution of pipelines for performance and cost-efficiency.
- Windowing and Triggers: Allows handling of streaming data with mechanisms to manage data based on time windows and event triggers.
5. Integration with Google Cloud
- Seamless Integration: Integrates with other Google Cloud services such as BigQuery, Cloud Storage, Pub/Sub, AI Platform, and more.
- Security and Compliance: Leverages Google Cloud’s robust security features, including encryption, IAM, and compliance certifications.
Data Ingestion in GCP
Data ingestion serves as the initial step in the Gcp cloud data flow process within Google Cloud Platform (GCP), encompassing the collection and importing of data from various sources into the GCP environment. Effective data ingestion lays the foundation for downstream processing, storage, and analysis, making it a critical component of any data-driven workflow.
Streaming Data Ingestion
Streaming data ingestion involves the continuous collection and processing of data in real-time as it is generated by various sources such as IoT devices, sensors, application logs, or social media feeds. Google Cloud Pub/Sub emerges as a fundamental service for streaming data ingestion in GCP, offering reliable and scalable message queuing capabilities.
Google Cloud Pub/Sub: Google Cloud Pub/Sub is a fully managed messaging service that enables asynchronous communication between applications and services. With Pub/Sub, organizations can decouple data producers from consumers, allowing for seamless integration of streaming data sources into data processing pipelines. Pub/Sub provides features such as at-least-once delivery semantics, message ordering, and horizontal scalability, making it ideal for building resilient and scalable streaming data ingestion workflows.
Advantages of Streaming Data Ingestion
- Real-time Insights: Streaming data ingestion enables organizations to capture and process data in real-time, allowing for immediate insights and actions based on up-to-date information.
- Low Latency: By minimizing the time between data generation and analysis, streaming data ingestion facilitates low-latency processing, making it ideal for use cases such as fraud detection, monitoring, and personalization.
- Scalability: Google Cloud Pub/Sub offers horizontal scalability, allowing organizations to handle varying volumes of streaming data without manual intervention or infrastructure management.
Batch Data Ingestion
Batch data ingestion involves the periodic import of data in predefined batches, typically from on-premises systems, legacy databases, or other cloud environments. Google Cloud Storage(GCS) serves as a versatile storage solution for batch data ingestion in GCP, offering scalable and durable object storage capabilities.
Google Cloud Storage (GCS): Google Cloud Storage provides a highly available and cost-effective platform for storing batch data prior to processing. Organizations can upload data to GCS in batch form using tools such as the gsutil command-line utility, the Google Cloud Console, or third-party applications. GCS offers features such as multi-regional replication, lifecycle management, and fine-grained access control, making it suitable for a wide range of batch data ingestion use cases.
Advantages of Batch Data Ingestion
- Robustness: Batch data ingestion ensures the reliability and consistency of data imports by processing data in predefined batches, reducing the risk of data loss or corruption.
- Cost-Effectiveness: Batch data ingestion can be more cost-effective than streaming ingestion for certain use cases, as it allows organizations to optimize resource utilization and minimize operational costs.
- Compatibility: Batch data ingestion supports the import of large volumes of data from diverse sources, making it suitable for migrating existing datasets to GCP or integrating with legacy systems.
Choosing Between Streaming and Batch Ingestion
The choice between streaming and batch data ingestion depends on various factors, including the nature of the data, latency requirements, and use case considerations. While streaming ingestion offers real-time insights and low latency, batch ingestion provides robustness, cost-effectiveness, and compatibility with existing systems.
In practice, organizations often employ a hybrid approach to data ingestion, leveraging both streaming and batch methods to accommodate diverse data sources and processing requirements. By combining the strengths of streaming and batch data ingestion in GCP, organizations can build resilient and scalable data ingestion pipelines that meet the demands of modern data-driven workflows.
In the subsequent sections of this article, we will explore the next stages of the data flow in GCP, including data processing, storage, analysis, and visualization. By understanding the fundamentals of data ingestion and its role in the broader context of data flow in GCP, organizations can lay the groundwork for building robust and scalable data-driven solutions that drive business success in the digital age.
Data Processing and Transformation
Once data is provided into Google Cloud Platform (GCP), the next crucial step in the data flow journey is processing and transforming the data to extract meaningful insights and prepare it for further analysis. Data processing involves applying various operations, transformations, and computations to raw data, shaping it into a format suitable for analysis and decision-making. In GCP, data processing is facilitated by Google Cloud Dataflow, a fully managed service based on the Apache Beam programming model.
Apache Beam
Apache Beam serves as the foundation for data processing in GCP, providing a unified programming model for building batch and streaming data processing pipelines. By offering a consistent API and execution model across different processing engines, Apache Beam enables developers to write data processing logic once and execute it on multiple execution environments, including Google Cloud Dataflow, Apache Spark, and Apache Flink.
- Unified Programming Model: Apache Beam abstracts the complexities of distributed data processing, allowing developers to focus on writing business logic without worrying about the underlying infrastructure. By providing a unified programming model for both batch and streaming processing, Apache Beam simplifies the development and deployment of data processing pipelines in GCP.
- Scalability and Performance: Apache Beam’s distributed processing model enables horizontal scalability, allowing data processing pipelines to scale dynamically to handle varying volumes of data. By automatically parallelizing computations and optimizing resource utilization, Apache Beam delivers high performance and efficiency, even for large-scale data processing workloads.
Google Cloud Dataflow
Google Cloud Dataflow extends the capabilities of Apache Beam by offering a fully managed service for executing data processing pipelines in GCP. With Dataflow, organizations can build, deploy, and monitor data processing workflows at scale without the need for infrastructure management.
- Fully Managed Service: Google Cloud Dataflow handles the complexities of infrastructure provisioning, scaling, and monitoring, allowing developers to focus on writing data processing logic. By abstracting away the operational overhead of managing clusters and resources, Dataflow enables organizations to accelerate time-to-insight and reduce total cost of ownership.
- Optimized Performance: Google Cloud Dataflow leverages Google’s infrastructure and distributed computing expertise to deliver optimized performance for data processing workloads. By dynamically allocating resources and optimizing data shuffling and parallelization, Dataflow ensures efficient execution of data processing pipelines, even for complex analytical tasks.
Data Processing Pipelines
Data processing pipelines in GCP are typically composed of a series of processing stages, each performing specific operations or transformations on the input data. These stages may include tasks such as data cleansing, enrichment, aggregation, and analysis, depending on the requirements of the use case.
- Data Transformation: Data processing pipelines in GCP often involve transforming raw data into a format suitable for analysis and visualization. This may include tasks such as parsing, filtering, aggregating, and joining data from multiple sources to derive actionable insights.
- Real-time and Batch Processing: Google Cloud Dataflow supports both real-time and batch processing modes, allowing organizations to choose the most appropriate processing paradigm based on their latency requirements and use case considerations. Real-time processing enables organizations to analyze streaming data in near real-time, while batch processing allows for the analysis of historical data in large batches.
Data Storage Solutions
Data storage is a fundamental aspect of data flow within Google Cloud Platform (GCP), providing the foundation for persisting and managing data assets throughout their lifecycle. GCP offers a diverse range of storage solutions tailored to accommodate various data types, use cases, and performance requirements, enabling organizations to store and access data efficiently at scale.
Google Cloud Storage (GCS)
Google Cloud Storage serves as a versatile and scalable object storage solution within GCP, offering durable and highly available storage for a wide range of data types, including unstructured data such as images, videos, and log files.
- Scalability and Durability: Google Cloud Storage is designed for scalability and durability, providing organizations with a reliable platform for storing petabytes of data with high availability and fault tolerance. With features such as multi-regional replication and object versioning, GCS ensures data integrity and resilience against hardware failures and data corruption.
- Cost-Effectiveness: Google Cloud Storage offers a flexible pricing model based on usage, allowing organizations to optimize storage costs based on their specific requirements. With features such as lifecycle management and storage classes, GCS enables organizations to tier data storage based on access frequency and retention policies, minimizing storage costs without sacrificing performance.
Google Cloud Bigtable
Google Cloud Bigtable is a fully managed NoSQL database service optimized for high-throughput, low-latency workloads, such as time series data, machine learning, and IoT applications.
- High Performance: Google Cloud Bigtable delivers high performance and scalability for read and write-heavy workloads, supporting millions of operations per second with sub-millisecond latency. By leveraging Google’s distributed infrastructure, Bigtable ensures consistent performance and availability, even for large-scale datasets.
- NoSQL Capabilities: Google Cloud Bigtable offers flexible schema design and support for wide-column data models, making it suitable for a wide range of use cases, including time series data, sensor data, and real-time analytics. With features such as row-level transactions and automatic sharding, Bigtable provides developers with the flexibility and scalability to build scalable and reliable applications.
Google Cloud BigQuery
Google Cloud BigQuery is a fully managed data warehouse service that enables organizations to analyze massive datasets using SQL queries with lightning-fast performance.
- Serverless Architecture: Google Cloud BigQuery offers a serverless architecture, eliminating the need for infrastructure provisioning and management. By abstracting away the complexities of cluster management, BigQuery enables organizations to focus on analyzing data and deriving insights without worrying about infrastructure overhead.
- Scalability and Performance: Google Cloud BigQuery is built for scalability and performance, allowing organizations to analyze terabytes to petabytes of data with blazing-fast SQL queries. With features such as columnar storage, automatic query optimization, and parallel processing, BigQuery delivers consistent performance and low latency, even for complex analytical queries.
Choosing the Right Storage Solution
The choice of storage solution within GCP depends on various factors, including data volume, access patterns, performance requirements, and cost considerations. Organizations should evaluate their specific use case requirements and choose the storage solution that best meets their needs in terms of scalability, durability, performance, and cost-effectiveness.
Data Analysis and Visualization
Data analysis and visualization are integral components of the data flow process within Google Cloud Platform (GCP), enabling organizations to derive actionable insights and communicate findings effectively. GCP offers a range of tools and services for analyzing and visualizing data, empowering organizations to explore, analyze, and visualize large datasets with ease.
Google Cloud BigQuery
Google Cloud BigQuery serves as a fully managed data warehouse solution within GCP, enabling organizations to analyze massive datasets using standard SQL queries with lightning-fast performance.
- Ad-Hoc Querying : Google Cloud BigQuery allows users to run ad-hoc SQL queries against large datasets in real-time, enabling exploratory data analysis and iterative query refinement. With its serverless architecture and scalable infrastructure, BigQuery enables organizations to derive insights quickly and efficiently without the need for manual tuning or optimization.
- Real-Time Analytics : Google Cloud BigQuery supports real-time analytics using features such as continuous streaming ingestion and table decorators. Organizations can analyze streaming data in real-time and derive actionable insights on-the-fly, enabling timely decision-making and rapid response to changing business conditions.
Data Visualization Tools
In addition to data analysis, GCP offers a range of data visualization tools for creating interactive dashboards, reports, and visualizations to communicate insights effectively.
- Google Data Studio: Google Data Studio is a fully managed data visualization platform that allows users to create interactive dashboards and reports using data from various sources, including Google Cloud BigQuery, Google Sheets, and external databases. With its drag-and-drop interface and rich visualization options, Data Studio enables organizations to create compelling visualizations and share insights with stakeholders.
- Integration with BI Tools: Google Cloud Platform integrates seamlessly with popular business intelligence (BI) tools such as Tableau, Looker, and Power BI, enabling organizations to leverage their existing BI investments and extend their analytics capabilities with GCP’s scalable infrastructure and advanced analytics services.
Advanced Analytics and Machine Learning
Google Cloud Platform offers advanced analytics and machine learning capabilities to enable organizations to extract deeper insights and unlock new opportunities from their data.
- BigQuery ML: Google Cloud BigQuery ML allows users to build and deploy machine learning models directly within BigQuery using standard SQL queries. Organizations can train machine learning models on large datasets and make predictions in real-time, enabling predictive analytics and personalized recommendations without the need for separate infrastructure or data movement.
- AI Platform: Google Cloud AI Platform provides a suite of machine learning services and tools for building, training, and deploying machine learning models at scale. With features such as AutoML for automating model development and AI Platform Notebooks for collaborative model development, organizations can accelerate their machine learning initiatives and drive innovation with AI.
Security and Compliance
Ensuring the security and compliance of data flow processes within Google Cloud Platform (GCP) is paramount for organizations operating in today’s data-driven landscape. Data flow in GCP offers a robust set of security features and compliance certifications to help organizations protect their data assets, maintain regulatory compliance, and mitigate security risks effectively.
Identity and Access Management (IAM)
Google Cloud Platform provides a comprehensive Identity and Access Management (IAM) system that enables organizations to manage access to resources securely. IAM allows organizations to control who has access to GCP resources and what actions they can perform, reducing the risk of unauthorized access and data breaches.
- Role-Based Access Control: IAM uses role-based access control (RBAC) to assign permissions to users, groups, and service accounts based on their roles and responsibilities. Organizations can define custom roles with granular permissions to enforce the principle of least privilege and minimize the risk of data exposure.
- Resource Hierarchy: IAM organizes resources within a hierarchical structure, allowing organizations to define access policies at the project, folder, and organization levels. This hierarchical approach enables organizations to enforce consistent access controls across their entire GCP environment, ensuring compliance with security policies and regulations.
Encryption and Data Protection
Google Cloud Platform offers robust encryption and data protection mechanisms to safeguard data at rest and in transit, protecting sensitive information from unauthorized access and disclosure.
- Encryption at Rest: GCP encrypts data at rest by default using industry-standard encryption algorithms such as AES-256. Organizations can also use customer-managed encryption keys (CMEK) or customer-supplied encryption keys (CSEK) to control encryption keys and ensure data sovereignty and compliance.
- Encryption in Transit: GCP encrypts data in transit using Transport Layer Security (TLS) to secure communications between clients and GCP services. By encrypting data in transit, GCP helps organizations protect sensitive information from interception and tampering during transmission over public networks.
Data Governance and Compliance
Google Cloud Platform provides a range of data governance and compliance tools to help organizations meet regulatory requirements and industry standards, such as GDPR, HIPAA, and SOC 2.
- Data Loss Prevention (DLP): Google Cloud DLP offers a suite of tools for identifying and protecting sensitive data, such as personally identifiable information (PII), credit card numbers, and health records. DLP helps organizations classify and mask sensitive data, monitor data access and usage, and enforce data protection policies to prevent data breaches and compliance violations.
- Compliance Certifications: Google Cloud Platform maintains a comprehensive set of compliance certifications and attestations, including ISO 27001, SOC 2, HIPAA, and GDPR, demonstrating its commitment to security and compliance. These certifications provide assurance to organizations that GCP meets stringent security and privacy requirements and adheres to industry best practices for data protection and governance.
Security Best Practices
In addition to built-in security features and compliance certifications, Google Cloud Platform offers a range of security best practices and guidelines to help organizations strengthen their security posture and mitigate security risks effectively.
- Security Controls : GCP provides a set of security controls and recommendations for securing GCP resources, such as virtual machines, storage buckets, and databases. Organizations can use tools such as Security Command Center and Cloud Security Scanner to assess their security posture, identify vulnerabilities, and remediate security issues proactively.
- Incident Response : GCP offers incident response services and tools to help organizations detect, investigate, and respond to security incidents effectively. With features such as Cloud Monitoring, Cloud Logging, and Cloud Audit Logs, organizations can monitor and analyze their GCP environment for suspicious activities and security threats, enabling rapid incident response and mitigation.
Conclusion
In conclusion, data flow within Google Cloud Platform (GCP) is a multifaceted process that encompasses the seamless movement, processing, storage, analysis, and protection of data assets within a secure and compliant environment. Data flow in GCP offers a comprehensive suite of services and tools tailored to meet the diverse needs of organizations operating in today’s data-driven landscape, empowering them to unlock the full potential of their data assets and drive business success.
From data ingestion and processing using services such as Dataflow in GCP, to storage and analysis with solutions like Google Cloud Storage and BigQuery, GCP provides organizations with the scalability, flexibility, and agility needed to navigate the complexities of modern data flow requirements.
Furthermore, GCP’s robust security and compliance features, including identity and access management, encryption, data loss prevention, and compliance certifications, enable organizations to protect their data assets, maintain regulatory compliance, and mitigate security risks effectively. By adhering to security best practices and leveraging GCP’s built-in security controls and recommendations, organizations can establish a strong security posture and build trust with customers, partners, and regulators.
As organizations continue to embrace digital transformation and harness the power of data to drive innovation and competitive advantage, Google Cloud Platform remains a trusted partner in enabling data flow at scale, empowering organizations to thrive in the digital age.
FAQ'S
Data flow in GCP refers to the movement of data within the Google Cloud ecosystem, including ingestion, processing, storage, and analysis.
The primary components include data sources, data sinks, data processing services such as Cloud Dataflow or Dataprep, and storage options like Cloud Storage or BigQuery.
Data flow often begins with data ingestion, where data is collected from various sources such as IoT devices, databases, or logs.
Common methods include streaming data ingestion using services like Pub/Sub or batch ingestion using tools like Cloud Storage Transfer Service.
Data can be processed using managed services like Cloud Dataflow for batch and stream processing or Dataprep for data preparation and cleansing.
Cloud Dataflow is a fully managed service for executing Apache Beam pipelines, enabling both batch and stream processing of data at scale.
Batch processing involves processing a fixed amount of data at once, while stream processing involves processing data in real-time as it arrives.
Data can be stored in various storage options provided by GCP, such as Cloud Storage for object storage, Bigtable for NoSQL data, and BigQuery for data warehousing.
Cloud Storage provides scalable object storage for storing and retrieving data, serving as a central repository for data within GCP.
Data movement can be facilitated using connectors or APIs provided by GCP services, ensuring seamless integration between different components of the data flow pipeline.
Best practices include choosing the appropriate data processing and storage services based on workload requirements, optimizing data formats for efficiency, and leveraging managed services for automation and scalability.
GCP offers various security features such as encryption, identity and access management (IAM), and compliance certifications to ensure data security and regulatory compliance throughout the data flow process.
GCP provides tools like Stackdriver Monitoring and Logging for real-time monitoring and troubleshooting, as well as Dataflow Monitoring and Visualization for monitoring Dataflow pipelines.
Yes, data flow pipelines can be automated using tools like Cloud Composer or Cloud Scheduler for scheduling and orchestrating data processing tasks.
Data transformation and enrichment can be achieved using services like Cloud Dataflow, which allows for the application of custom logic and transformations to data streams.
Pub/Sub acts as a messaging service for decoupling data producers from data consumers, enabling scalable and reliable communication between different components of the data flow pipeline.
Data flow supports real-time analytics by enabling stream processing of data using services like Cloud Dataflow, allowing for the analysis of data as it is generated.
Use cases include real-time analytics, IoT data processing, ETL (Extract, Transform, Load) pipelines, log processing, and machine learning model training.
Data flow services often provide features for tracking data lineage and managing metadata, allowing users to trace the origins of data and understand its transformation throughout the pipeline.
Alternatives include services like Dataprep for data preparation, Apache Beam for building custom data processing pipelines, and managed Hadoop services like Dataproc for running Apache Spark and Hadoop clusters.